Ein Leitfaden zu Robots Meta Tags für Programmatic SEO

Robots meta tags sind einfache Code-Schnipsel, die du in das HTML deiner Webseite einfügst. Stell dir sie als Ampeln für Suchmaschinen vor. Sie geben klare, direkte Anweisungen, ob eine bestimmte Seite in den Suchergebnissen angezeigt werden soll oder ob den Links darauf gefolgt werden soll. Diese Seitensteuerung auf Page-Ebene ist der Schlüssel zur Verwaltung einer Website, insbesondere wenn du Inhalte in großem Maßstab erstellst.
Was sind Robots Meta Tags und warum sind sie wichtig?

Stell dir vor, deine Website ist ein großes Wohnhaus. Deine robots.txt-Datei ist das Schild am Haupteingang und teilt Lieferfahrern (Crawlers der Suchmaschinen) mit, welche ganzen Etagen tabu sind. Sie gibt breite, site-weite Regeln vor.
Robots meta tags hingegen sind die "Bitte nicht stören"-Schilder an einzelnen Apartmenttüren. Eine Seite mit einem noindex-Tag ist wie ein Raum mit diesem Schild – der Crawler weiß, dass er überspringen soll, selbst wenn das Tor ihn auf diese Etage lässt. Gerade diese präzise, seitenweise Steuerung macht diese Tags so kraftvoll und praktisch.
Die Rolle von Robots Meta Tags im SEO
Das Verständnis dieser Befehle ist entscheidend für modernes SEO. Sie geben dir eine präzise Kontrolle über die Sichtbarkeit deiner Website und helfen dir, Suchmaschinen zu deinen besten Inhalten zu leiten.
Darum sind sie so nützlich:
- Verhinderung von Duplicate Content: Hast du printerfreundliche Versionen einer Seite oder Seiten mit sehr ähnlichem Inhalt, kannst du ein
noindex-Tag verwenden, um Google mitzuteilen, welche die Hauptversion ist, die angezeigt werden soll. - Verwaltung des Crawl Budget: Suchmaschinen haben begrenzte Zeit, deine Seite zu crawlen. Indem du ihnen sagst, niedrigwertige Seiten zu ignorieren (wie interne Suchergebnisse oder Login-Seiten), stellst du sicher, dass sie ihre Zeit auf deinen wichtigsten Content verwenden.
- Private Seiten privat halten: Staging-Seiten, "thank you"-Seiten nach einem Kauf oder interne Admin-Bereiche sollten nicht in öffentlichen Suchergebnissen erscheinen. Ein
noindex-Tag ist das ideale Werkzeug, um sie verborgen zu halten.
Im Kern ist ein robots meta tag deine direkte Kommunikationsleitung zu einer Suchmaschine für eine einzelne Seite. Es ermöglicht dir, klare Regeln festzulegen und sicherzustellen, dass dein Content genau so erscheint, wie du es beabsichtigst.
Gängige Robots Meta Tag Directives
Um es einfach zu machen, hier eine kurze Cheatsheet mit den gängigsten Anweisungen, die du Suchmaschinen-Crawlers geben kannst.
| Directive | Was sie Crawlersn mitteilt | Gängiger Anwendungsfall |
|---|---|---|
index |
"Fühl dich frei, diese Seite in deinen Suchergebnissen anzuzeigen." | Standard für die meisten öffentlichen Seiten. |
noindex |
"Bitte diese Seite nicht in deinen Suchergebnissen anzeigen." | Danksagungsseiten, dünner Content, interne Suchergebnisse. |
follow |
"Du kannst den Links auf dieser Seite folgen, um weitere Seiten zu entdecken." | Standard-Einstellung, verwendet mit index oder noindex. |
nofollow |
"Folge keinen Links auf dieser Seite oder überlasse ihnen kein Equity." | Bezahlte Links, nutzererzeugter Content, unvertrauenswürdige Links. |
noarchive |
"Zeige keinen gecachten Link für diese Seite in Suchergebnissen." | Seiten mit häufig aktualisierten, zeitempfindlichen Daten. |
nosnippet |
"Zeige kein Text-Snippet oder Video-Vorschau in Suchergebnissen." | Wenn du Benutzer zwingen willst, zu klicken, um den Inhalt zu sehen. |
Diese Anweisungen lassen sich auch kombinieren. Zum Beispiel ist noindex, follow ein sehr häufiger und nützlicher Befehl, der eine Seite vor Suchergebnissen versteckt, ihre Links jedoch weiterhin von Suchmaschinen entdeckt werden lässt.
Warum pSEO-Praktiker diese Tags meistern müssen
Für programmatic SEO (pSEO), bei dem du möglicherweise tausende Seiten automatisch generierst, ist dieses Maß an Kontrolle entscheidend. Das manuelle Prüfen jeder Seite ist unmöglich. Stattdessen erstellst du intelligente Regeln, die automatisch die richtigen robots meta tags basierend auf den Daten einer Seite anwenden, z. B. ihrem Wortumfang oder ob sie Bilder hat.
Beispielsweise kannst du automatisch ein noindex-Tag auf allen neuen Seiten setzen, die weniger als 200 Wörter haben, um niedrige Qualität von "Stub"-Seiten daran zu hindern, den Ruf deiner Website zu schädigen. So verwaltest du Qualität in großem Maßstab. Für einen tieferen Einblick, wie diese Tags in das größere Bild passen, sieh dir unseren Leitfaden zu den Fundamentals von Indexing und Crawling an.
Verstehen der Kern-Directives

Im Mittelpunkt von robots meta tags stehen vier einfache Befehle. Stell sie dir wie On/Off-Schalter vor, die zwei zentrale Aktionen steuern: Ob eine Seite in den Suchergebnissen erscheinen soll und ob die Links auf dieser Seite verfolgt werden sollen.
Das Verständnis dieser vier Direktiven ist der erste Schritt, echte Kontrolle über die Sichtbarkeit deiner Website zu gewinnen. Lass uns jeden einzelnen entmystifizieren.
Die Indexing-Directives: index und noindex
Diese beiden Anweisungen sind Gegensätze und die leistungsstärksten Befehle in deinem SEO-Wundzeug. Sie sagen Google, ob eine Seite angezeigt werden darf oder nicht.
index: Das ist der Standard. Es ist wie eine offene Einladung, Suchmaschinen zu sagen: "Bitte füge diese Seite zu deinen Suchergebnissen hinzu." Wenn du kein robots tag hinzufügst, nehmen Suchmaschinen an, dass duindexmeinst.noindex: Das ist eine direkte Anordnung. Sie sagt Suchmaschinen: "Du kannst diese Seite besuchen, zeige sie aber nicht in öffentlichen Suchergebnissen." Es ist das digitale Äquivalent zu einem Schild "Staff Only".
Eine der praktischsten Kombinationen ist noindex, follow. Dies sagt Google, die Seite zu verstecken, aber trotzdem ihren Links zu folgen, um weitere wichtige Inhalte zu finden. Für eine tiefe Einarbeitung kannst du mehr darüber erfahren, wie du strategisch noindex Tags verwendest.
Wann man noindex verwendet
Der noindex-Tag ist ein Lebensretter im programmatic SEO. Wenn du tausende Seiten automatisch generierst, werden einige zwangsläufig dünn an Inhalt sein oder nicht öffentlich angezeigt werden sollen. Das ist, wo noindex dein bester Freund ist.
Er eignet sich perfekt für:
- Dünner Content Pages: Programmgenerierte Seiten, die noch nicht genügend eindeutigen Wert haben.
- Interne Suchergebnisse: Die Seiten, die entstehen, wenn ein Nutzer auf deiner eigenen Site sucht.
- Danke-Seiten: Einfache Bestätigungsseiten, die ein Nutzer nach der Anmeldung oder einem Kauf sieht.
- Staging-Umgebungen: Testversionen deiner Website, bevor sie live gehen.
Um vollständig zu verstehen, wie man Seiten außerhalb des Index hält, lohnt es sich, verwandte Controls wie die noindex-Direktive in robots.txt zu prüfen, da dies hilft zu klären, wie verschiedene Regeln interagieren können.
Die Link-Following Directives: follow und nofollow
Als Nächstes folgen die Befehle, die Suchmaschinen sagen, wie sie mit den Links auf einer Seite umgehen sollen. Diese Anweisungen steuern den Fluss von Autorität (oft als "link equity" bezeichnet) von einer Seite zur nächsten.
follow: Das ist der Standard. Es sagt Crawlern: "Gehe voran, folge den Links auf dieser Seite, um weitere Inhalte zu entdecken."nofollow: Diese Direktive weist Crawler an: "Folge keinen der Links auf dieser Seite oder leite kein Vertrauen durch sie weiter."
Google behandelt nofollow heute eher als starken Hinweis denn als strikte Regel, aber es bleibt ein wichtiges Instrument, um die Natur deiner Links zu signalisieren. Besonders nützlich bei nutzererzeugtem Content wie Blog-Kommentaren, wo du nicht für potenziell spammy Websites bürgen möchtest.
Durch das Mischen und Kombinieren dieser einfachen Direktiven schaffst du spezifische Anweisungen. Zum Beispiel sagt
<meta name="robots" content="noindex, follow">Google: "Verstecke diese Seite in den Suchergebnissen, aber folge ruhig ihren Links, um weitere nützliche Seiten auf meiner Site zu finden."
Das Meistern dieser grundlegenden Befehle gibt dir die Macht, die Präsenz deiner Seite in Suchergebnissen präzise zu gestalten.
Robots Meta Tag vs. X-Robots-Tag
Wenn du Suchmaschinen Anweisungen gibst, kommt es auf eine einfache Frage an: Um welchen Dateityp handelt es sich? Sowohl der meta robots tag als auch der X-Robots-Tag können dieselben Befehle geben, wie noindex oder nofollow. Der einzige Unterschied ist wo und wie sie implementiert werden.
Stell dir einen starken meta robots tag wie eine Notiz vor, die auf der ersten Seite in einem Buch geschrieben steht. Du musst das Buch (die HTML-Seite) öffnen, um sie zu lesen. Das ist ideal für Webseiten, da sie mit HTML aufgebaut sind und einen <head>-Bereich haben, in dem diese Notizen gehören.
Der X-Robots-Tag hingegen ist wie eine helle Klebezettel am Außenseite einer Aktenmappe. Du siehst die Anweisung, noch bevor du die Datei öffnest. Das ist essentiell für Dateien, die kein HTML <head>-Bereich haben, wie ein PDF-Dokument, ein Bild oder ein Video.
Wofür man welches Tag verwendet
Die Wahl ist einfach und hängt vollständig vom Dateityp ab. Du verwendest eines oder das andere, niemals beides für dieselbe URL.
Meta Robots Tag: Das ist dein Standard für reguläre HTML-Webseiten. Du platzierst es direkt im Code der Seite, wodurch es leicht über deine Website-Plattform oder durch Bearbeiten des HTML implementierbar ist.
X-Robots-Tag: Das gilt für alle Nicht-HTML-Dateien. Da Dateien wie PDFs, Word-Dokumente oder Bilder keinen HTML
<head>-Bereich haben, kannst du kein Meta-Tag darin einfügen. Die Anweisung muss stattdessen über den HTTP-Header des Servers gesendet werden.
Die Hauptbotschaft lautet: Wenn es eine Web-Seite ist, verwende ein Meta Robots Tag. Wenn es eine Datei wie ein PDF oder ein Bild ist, musst du den X-Robots-Tag verwenden.
Praktische Implementierungsbeispiele
Zu sehen, wie jedes verwendet wird, macht es leicht zu verstehen.
Beispiel für ein Meta Robots Tag
Dieser Code-Snippet gehört in den <head>-Bereich deiner HTML-Seite. Er teilt allen Suchmaschinen mit, die Seite nicht zu indexieren, aber den Links darauf zu folgen.
<meta name="robots" content="noindex, follow">
Beispiel für einen X-Robots-Tag
Dies wird nicht in einer Datei hinzugefügt; es wird auf deinem Server konfiguriert. Für einen Apache-Server könntest du dies zu deiner .htaccess-Datei hinzufügen, um Suchmaschinen daran zu hindern, alle PDF-Dateien auf deiner Site zu indexieren.
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, follow"
</Files>
Diese Regel wirkt wie der Klebezettel auf jeder einzelnen PDF-Datei und teilt Crawlern mit, wie sie damit umgehen sollen. Für eine viel tiefere Einarbeitung sieh dir unseren Leitfaden zu technischen Meta-Tags an.
Wahl zwischen Meta Robots und X-Robots-Tag
Um die Entscheidung noch einfacher zu machen, hier ein schneller Vergleichstabelle, die dir hilft, jedes Mal die richtige Option zu wählen.
| Kriterium | Meta Robots Tag | X-Robots-Tag Header |
|---|---|---|
| Beste Verwendung | Standard-HTML-Webseiten. | Nicht-HTML-Dateien (PDFs, Bilder, Videos). |
| Implementierung | Im <head> der HTML-Datei platziert. |
Auf Server-Ebene konfiguriert (z. B. .htaccess). |
| Flexibilität | Seiten-spezifisch und einfach zu ändern für eine URL. | Kann Regeln auf ganze Dateitypen oder Verzeichnisse anwenden. |
| Gängiger Anwendungsfall | Noindexing einer dünnen Content-Seite oder einer staging URL. | Noindexing einer Bibliothek downloadable PDF-Anleitungen. |
Diese Tabelle sollte jegliche Verwirrung klären. Du wählst einfach die richtige Bereitstellungsmethode für deine Anweisungen basierend auf dem Inhaltstyp.
Wie du Robots Meta Tags für PSEO automatisierst
Die Handhabung robots meta tags für ein paar Seiten ist einfach. Aber wenn du eine programmatic SEO-Kampagne mit Tausenden von Seiten durchführst, ist manuelles Handeln unmöglich. Hier wird Automatisierung zu deiner Geheimwaffe, die einen riesigen Kopfschmerz in ein intelligentes, regelbasierendes System verwandelt, das für dich arbeitet.
Der Schlüssel liegt darin, nicht mehr seitenweise zu denken, sondern Regeln zu erstellen. Statt manuell einen noindex-Tag zu einer dünnen Seite hinzuzufügen, baust du ein System, das dies automatisch für jede Seite tut, die deiner Definition von "dünn" entspricht. Das ist leichter zugänglich, als es klingt, und erfordert kein tiefes Coding-Wissen.
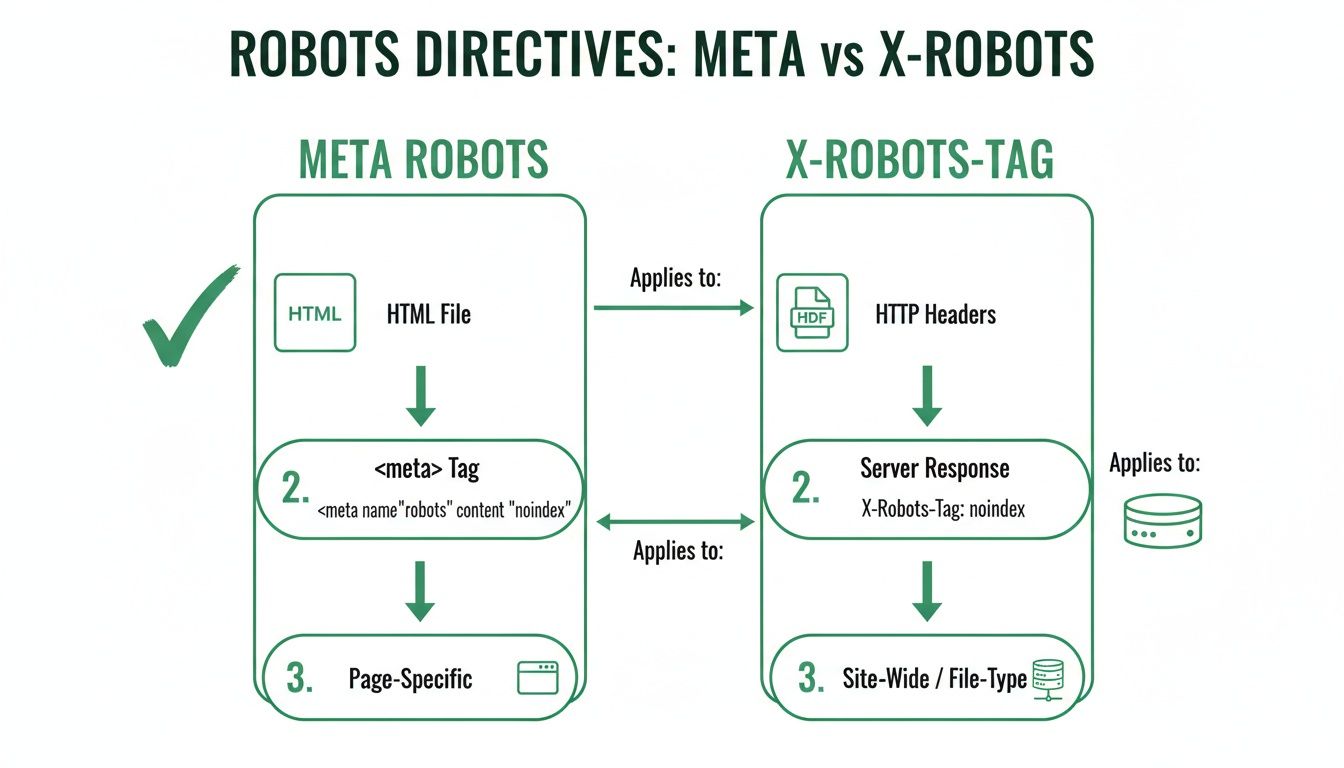
Dieses Diagramm zeigt, dass Meta-Tags in dein HTML gehen, während X-Robots-Tags für andere Dateien wie PDFs gesendet werden. Deine Automatisierungsregeln müssen diese Unterscheidung kennen, damit sie korrekt funktionieren.
Schritt 1: Programmatic SEO mit KI – der einfache Weg
Programmatic SEO mit KI klingt komplex, aber es geht wirklich um drei praktische Schritte:
- Daten beschaffen: Zuerst benötigst du Daten. Das könnte eine Liste von Produkten, Standorten oder Dienstleistungen sein. Du kannst diese Daten aus einem einfachen Spreadsheet (wie Google Sheets) oder einer fortgeschrittenen Datenbank beziehen. Das ist dein Rohmaterial.
- KI zur Anreicherung der Daten nutzen: Hier macht KI dein Leben leichter. Du kannst Tools wie ChatGPT oder spezialisierte KI-Schreibplattformen verwenden. Gib der KI eine Zeile aus deinem Spreadsheet (z. B. "blaue Laufschuhe, Größe 10") und eine einfache Aufforderung wie: "Schreibe eine kurze, freundliche Produktbeschreibung für diese Schuhe." Die KI erzeugt für jeden Eintrag einzigartigen Content und verwandelt deine Rohdaten in reichhaltigen Text.
- Seiten erstellen: Schließlich verwendest du eine Seitenvorlage, um automatisch eine einzigartige Seite für jede Zeile deiner angereicherten Daten zu erstellen. Viele Website-Builder (wie Webflow oder WordPress mit bestimmten Plugins) können direkt mit einem Google Sheet verbunden werden und diese Seiten für dich generieren, ohne Programmierkenntnisse.
Schritt 2: Setze "If-Then"-Regeln für deine Robots Tags
Sobald deine Seiten erstellt werden, musst du ihre Qualität steuern. Hier verwendest du einfache "if-then"-Logik in deiner Seitenvorlage.
Stell es dir vor wie das Festlegen von Regeln in einem E-Mail-Filter. Zum Beispiel kannst du eine Regel erstellen, die automatisch ein noindex, follow-Tag hinzufügt, wenn eine Seite weniger als 300 Wörter hat. Das hält deine niedrigen Wert-Seiten aus dem Index von Google, lässt aber Crawlern weiterhin Links zu deinem besseren Content folgen.
Hier sind einige praktische Beispiele:
- Content Freshness: Automatisch ein
noindex-Tag auf alle Seiten anwenden, die jünger als eine Woche sind. So bekommen sie Zeit, vollständig aufgebaut zu werden, bevor Suchmaschinen sie sehen. - Data Completeness: Wenn eine Produktseite wichtige Informationen wie Preis oder Bild fehlt, kann eine Regel sie automatisch
noindexsetzen, bis die Daten vollständig sind. - AI-Generated Content Quality: Wenn dein KI-generierter Text zu kurz ist oder eine Qualitätskontrolle nicht besteht, kannst du die Seite
noindexsetzen, bis sie verbessert wird.
Für eine tiefe Einführung in das Einrichten solcher Systeme ist unser Leitfaden zum Aufbau einer PSEO-Datenpipeline der perfekte Anfang.
Indem du diese Regeln einmal auf Template-Ebene festlegst, stellst du sicher, dass jede einzelne Seite – egal ob 100 oder 100.000 – die richtigen Anweisungen erhält, ohne dass du etwas tun musst. Das ist es, worum skalierbares SEO geht.
Zukunftssicherung durch Automatisierung
Automatisierung bedeutet nicht nur traditionelles SEO. Mit dem Aufstieg von KI ergeben sich neue Herausforderungen, wie Unternehmen, die deinen Content verwenden, um ihre KI-Modelle zu trainieren. Eine intelligente programmatic-Strategie kann deinen Content skalieren schützen.
Du kannst eine Regel einrichten, die automatisch Direktiven wie noai oder noimageai zu allen Seiten hinzufügt. Das teilt KI-Crawlern mit, deinen Text oder deine Bilder nicht zum Trainingszweck zu verwenden, und schützt den einzigartigen Wert, den du aufgebaut hast. Diese Regel einmal zu setzen stellt sicher, dass deine gesamte Seite nicht einfach als kostenloses Trainingsmaterial für Big Tech dient. Es geht darum, einfache Automatisierung zu nutzen, um den langfristigen Wert deiner Site zu bewahren.
Vermeidung häufiger Implementierungsfehler
Selbst einfache Werkzeuge können große Probleme verursachen, wenn sie falsch verwendet werden. Mit robots meta tags kann schon ein kleiner Fehler deine wichtigsten Seiten aus Googles Index verschwinden lassen. Lass uns die häufigsten Stolperfallen und wie man sie auf einfache, nicht-technische Weise vermeidet, durchgehen.
Der Konflikt-Signal-Fehler
Dies ist die häufigste Falle. Sie passiert, wenn du eine URL in deiner robots.txt-Datei blockierst und gleichzeitig einen noindex-Tag auf derselben Seite hinzufügst.
Stell es dir so vor: Deine robots.txt-Datei ist der Türsteher an der Vordertür. Wenn du dem Türsteher sagst, Google nicht reinzulassen, kann es niemals hineingehen, um das "Do Not List This Page" (noindex) Schild an der Wand zu lesen. Wenn die Seite bereits im Index von Google war, wird sie dort bleiben, weil der Crawler nicht zurück hereinkommen kann, um die neue Anweisung zu sehen.
Die Lösung: Um eine Seite zuverlässig aus den Suchergebnissen zu entfernen, musst du dem Crawling in
robots.txtausdrücklich erlauben. Dadurch kann Googlebot die Seite besuchen, dienoindex-Anweisung lesen und sie dann aus dem Index entfernen. Nutzenoindex, um zu steuern, was indexiert wird, undrobots.txt, um zu steuern, was gecrawlt wird – aber selten beides für dieselbe URL.
Der Syntax-Fehler
Suchmaschinen-Crawler sind sehr wörtlich. Sie folgen Anweisungen perfekt, aber nur, wenn sie korrekt geschrieben sind. Ein einfacher Tippfehler in deinem Meta-Tag kann es völlig nutzlos machen.
Häufige Fehler sind:
- Verwendung eines Semikolons statt eines Kommas:
<meta name="robots" content="noindex; follow"> - Rechtschreibfehler bei den Anweisungen:
<meta name="robots" content="noindx, follow"> - Platzierung des Tags außerhalb des
<head>-Bereichs deiner HTML.
Wenn du einen dieser Fehler machst, ignoriert der Crawler es und macht schlicht das, was er normalerweise tut: index und follow der Seite – genau das Gegenteil von dem, was du wolltest.
Der versehentliche Massen-De-Indexierungsfehler
Dies ist das Albtraumszenario für jedes programmatic SEO-Projekt. Es passiert üblicherweise, wenn eine globale Vorlage oder eine site-weite Einstellung falsch geändert wird. Zum Beispiel könnte ein Entwickler ein noindex-Tag zu einer Testseite hinzufügen und diese Änderung versehentlich auf die Live-Seite übertragen.
Plötzlich erhält jede Seite, die diese Vorlage verwendet, das noindex-Tag, und deine gesamte Site verschwindet aus Suchergebnissen. Die beste Vorgehensweise, um dies zu verhindern, ist vorsichtig zu sein und Änderungen zuerst an einer kleinen Charge nicht-kritischer Seiten zu testen. Prüfe sie in der Google Search Console und wende die Änderung erst dann auf deine gesamte Site an. Richtig angewendetes noindex stellt sicher, dass der Ruf deiner Marke auf stabilen, hochwertigen Seiten basiert. Weitere Einblicke zu digitalen Trends findest du in DataReportal's Analyse der digitalen Landschaft Deutschlands.
Wie du deine Robots Tags testest und auditest
Das Setzen deiner robots meta tags ist nur die Hälfte der Aufgabe. Wenn Suchmaschinen deine Anweisungen nicht korrekt lesen können, nützen sie nichts. Ein winziger Fehler in einer programmatic-Setup kann Tausende Seiten betreffen, daher sind regelmäßige Checks unerlässlich.
Stell es dir vor wie das Senden einer wichtigen Email. Du klickst nicht einfach auf "Senden" und hoffst das Beste; du prüfst deinen "Gesendet"-Ordner, um sicherzustellen, dass sie durchgegangen ist. Die Prüfung deiner Tags ist genau, wie du sicherstellst, dass Suchmaschinen deine Anweisungen erhalten und verstanden haben.
Deine praktische Audit-Checkliste
Das Audit einer großen, programmgenerierten Site muss nicht kompliziert sein. Mit den richtigen Tools und einem einfachen Ablauf findest du schnell Fehler, bevor sie Probleme verursachen.
Hier ist ein einfacher Ablauf, dem du folgen kannst:
Durchsuche deine Site: Nutze ein Tool wie Screaming Frog (es gibt eine kostenlose Version), um deine Webseite zu durchsuchen. Das liefert dir eine vollständige Liste aller Meta-Robots-Anweisungen auf all deinen Seiten.
Filtern und Verifizieren: Nach dem Crawlen filtere die Ergebnisse so, dass nur Seiten mit einer
noindex-Direktive angezeigt werden. So erhältst du eine klare Liste aller Inhalte, die du Suchmaschinen absichtlich verborgen hast.Abgleich mit Analytics: Jetzt der wichtigste Schritt. Nimm diese Liste von
noindex-Seiten und vergleiche sie mit deinen Website-Analytiken. Erhalten einige der Seiten Traffic aus Google-Suche? Falls ja, hast du einen Fehler gefunden, bei dem eine wertvolle Seite versehentlich blockiert wird.
Dieser Abgleich ist deine Sicherheitsnetz. Er hilft dir, Fehler zu finden, bei denen eine Regel zu breit angewendet wurde, damit du wichtige Seiten retten kannst, die versehentlich vor der Suche verborgen wurden.
Die Tools von Google für eine abschließende Prüfung
Nach deinem eigenen Crawling ist es immer klug, deine Seiten so zu sehen, wie Google sie sieht. Hier ist der Google Search Console dein bester Freund.
Das URL-Inspektions-Tool liefert dir einen direkten Bericht von Google. Gib einfach jede URL deiner Site ein, und es sagt dir genau, welche robots meta tags Google beim letzten Besuch gefunden hat. Das ist der ultimative Weg, um zu bestätigen, dass deine Anweisungen korrekt empfangen wurden.
Um das Beste aus diesem Feature herauszuholen, sieh dir unseren detaillierten Leitfaden zu der Navigation in Google Search Console für pSEO an. Und für einen breiteren Blick darauf, wie du deine Site gesund hältst, werfe einen Blick auf deinen ultimativen Leitfaden zu einem technischen SEO-Audit. Dieser methodische Ansatz gibt dir das Vertrauen, Fehler schnell zu finden und zu beheben.
Häufig gestellte Fragen
Selbst mit den Grundlagen bleiben einige Fragen zu robots meta tags oft offen. Klären wir alle verbleibenden Unklarheiten, damit du diese Befehle mit Zuversicht einsetzen kannst.
Kann ich mehrere Robots Meta Tags auf einer Seite verwenden?
Nein, du solltest pro Seite nur ein robots meta tag verwenden. Wenn du mehrere Tags einfügst, riskierst du, Suchmaschinen zu verwirren, was zu unvorhersehbaren Ergebnissen führen kann.
Um deine Anweisungen klar zu halten, kombiniere alles in einem einzigen <meta>-Tag im HTML <head>. Zum Beispiel statt zwei separater Tags, kombiniere sie so: <meta name="robots" content="noindex, nofollow">. So werden deine Anweisungen genau so verstanden, wie beabsichtigt.
Was ist der Unterschied zwischen Noindex und Robots.txt Disallow?
Dies ist ein häufiger Irrtum. Die einfachste Merkhilfe lautet: robots.txt disallow ist wie ein "Do Not Enter"-Schild an einer Tür. Es hindert Crawler daran, die Seite überhaupt zu besuchen.
Ein noindex-Tag lässt den Crawler hineingehen und sich umsehen, sagt ihm aber danach: "List diese Seite nicht in deinem öffentlichen Verzeichnis." Die Seite wird besucht, aber nicht in den Suchergebnissen angezeigt.
Wenn dein Ziel ist, eine Seite aus dem Googles Index zu entfernen, musst du unbedingt das
noindex-Tag verwenden und sicherstellen, dass die Seite in deinerrobots.txt-Datei nicht blockiert ist. Wenn du den Crawler blockierst, wird er deinenoindex-Anweisung nie sehen.
Wie lange dauert es, bis Google ein geändertes Robots-Tag sieht?
Dies hängt davon ab, wie oft Google deine Site besucht. Für eine große, häufig aktualisierte Website könnte eine Änderung innerhalb eines Tages oder zwei bemerkt werden. Für kleinere oder neuere Seiten kann es Tage oder sogar Wochen dauern.
Wenn du den Prozess beschleunigen musst, kannst du Google bitten, eine Seite erneut zu crawlen, indem du das URL-Inspektions-Tool in Google Search Console verwendest. Bedenke jedoch, dass dies nur eine Anfrage ist. Google entscheidet letztlich, wann erneut gecrawlt wird, daher ist Geduld erforderlich.
Bereit, deine Content-Strategie mit Präzision und Zuversicht zu skalieren? Das Programmatic SEO Hub bietet Guides, Templates und Tools, die du brauchst, um alles von robots meta tags bis hin zur vollständigen Automatisierung zu meistern. Zukunftssichere dein SEO unter https://programmatic-seo-hub.com/de.
Verwandte Artikel

Ein moderner Leitfaden für AI-gestütztes SEO Content Marketing
Im Kern dreht sich Content Marketing im Bereich SEO darum, die beste, hilfreichste Antwort auf die Fragen zu liefern, die Ihre idealen Kunden bei Google eingeben. Es ist die Kunst, wirklich nützliche...

Wachsen mit SEO für Content Marketing: Ein praktischer Leitfaden zur Skalierung Ihres Contents
Also, was genau ist SEO for content marketing? Stellen Sie es sich vor als das Erstellen und Teilen von wirklich nützlichem Content, der Menschen aus Suchmaschinen wie Google anzieht, mit dem...

Seo in Blogs: Ein praktischer Leitfaden für AI-getriebenes Wachstum
Blog SEO dreht sich darum, deine Artikel so abzustimmen, dass sie in Suchergebnissen höher ranken und einen stetigen Zustrom der richtigen Art von Besuchern auf deine Seite lenken. Es geht um mehr...